
Matters of Attention: What is Attention and How to Compute Attention in a Transformer Model
A comprehensive and easy guide to Attention in Transformer Models (with example code)

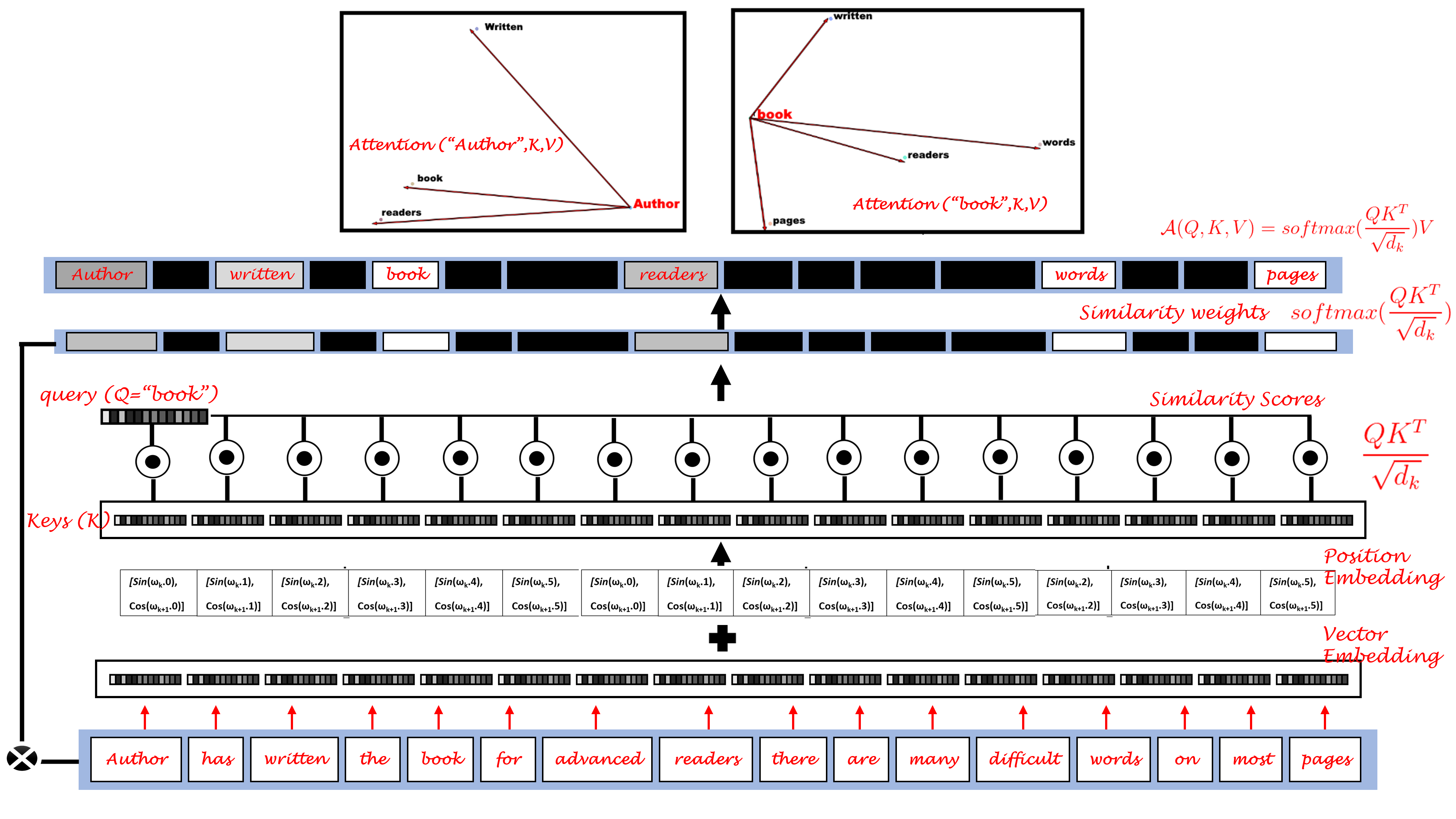
In this article, you will learn about Attention, its computation and role in a transformer network. You will also learn about vector embedding, position embedding and attention implementation in a text transformer. This will make use of concepts, “Transformers” and “Autoencoders”, so, if you would like to learn more about these topics then feel free to check out my earlier posts.
Keep reading with a 7-day free trial
Subscribe to Azad Academy to keep reading this post and get 7 days of free access to the full post archives.